When we started building Navionyx, our GPS tracking platform, everything looked simple.
A few vehicles, a few thousand location points, and basic tracking dashboards.
Fast forward a few months — we were dealing with:
-
100+ million GPS records
-
GBs of time-series data
-
Thousands of devices sending data continuously
-
A real-time dashboard that users expected to load instantly
This is the story of how we redesigned our database, architecture, and query strategy to scale reliably — without overengineering or throwing unnecessary infrastructure at the problem.
📌 The Real Challenge of GPS Systems
GPS tracking systems are deceptively hard to scale.
They are:
-
Write-heavy → constant inserts from devices
-
Read-heavy → dashboards polling frequently
-
Time-series driven → data grows forever
At scale, naïve designs lead to:
-
Slow
ORDER BYqueries -
Full table scans
-
EC2 CPU spikes
-
Dashboards taking seconds to load
We had to rethink how GPS data should be stored and queried.
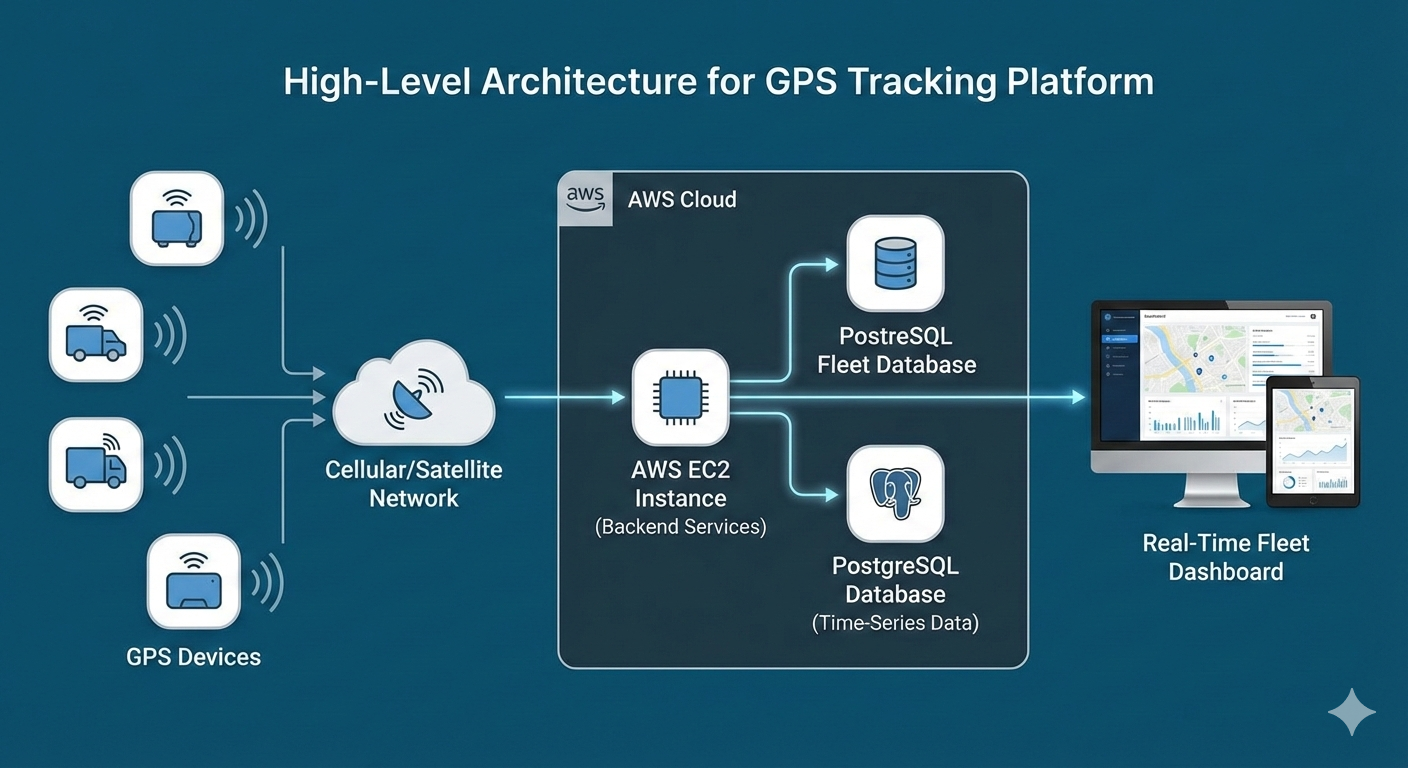
🧠 Designing GPS Data as Time-Series (Not Relational)
One of the first decisions we made was treating GPS data as append-only time-series data.
Key principles:
-
No updates, only inserts
-
Optimize for “latest point per vehicle”
-
Avoid unnecessary joins
Simplified schema:
This allowed PostgreSQL to do what it does best — fast writes and indexed reads.
⚡ PostgreSQL: The Unsung Hero
PostgreSQL handled our scale surprisingly well — once we used it properly.
Key features we relied on:
-
Composite indexes
-
Descending indexes
-
Table partitioning
-
Materialized views
-
Aggressive query optimization
One of the most impactful indexes we added:
This alone reduced our latest GPS fetch time from seconds to milliseconds.

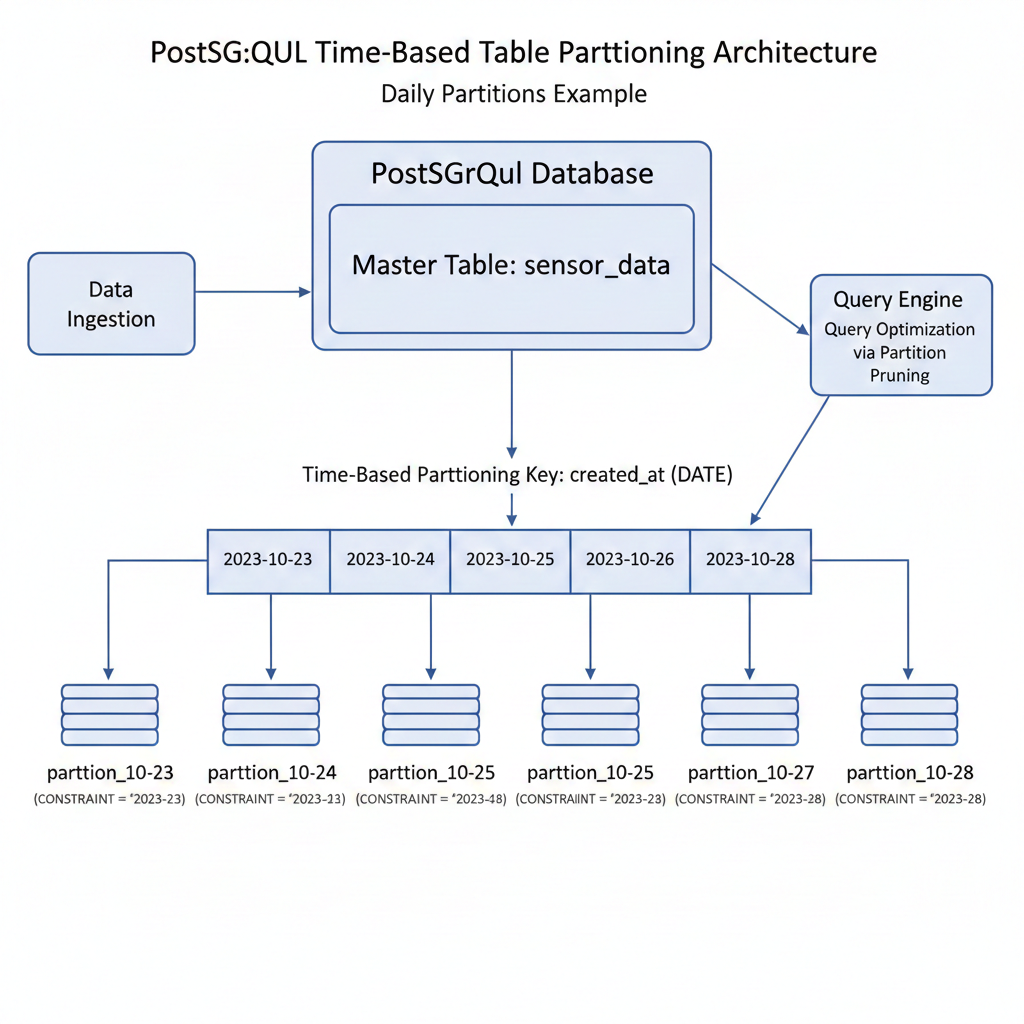
🧩 Partitioning: Making 100M Rows Feel Manageable
Instead of one massive table, we partitioned GPS data by date.
Why date-based partitioning works well for GPS:
-
Queries usually target recent data
-
Old data is rarely accessed
-
Automatic partition pruning reduces scans
Results:
-
Smaller index sizes per partition
-
Faster deletes and archiving
-
Predictable performance even as data grows
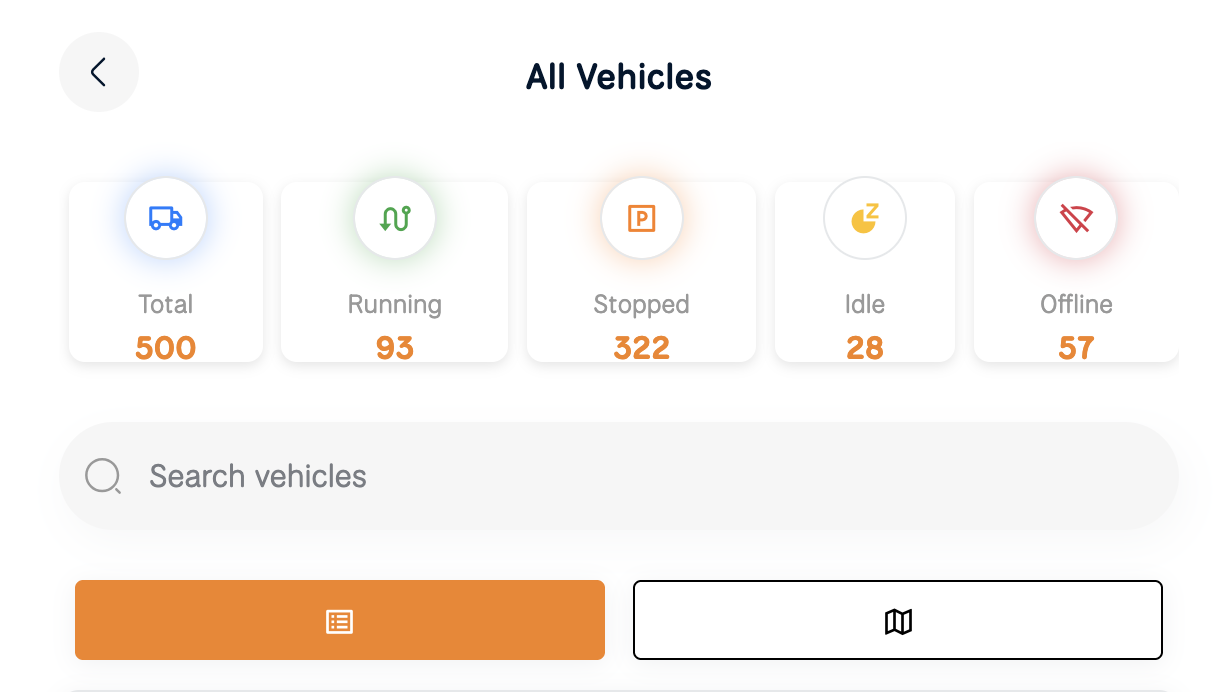
📊 The Dashboard Bottleneck
Our fleet dashboard shows:
-
Total vehicles
-
Running
-
Stopped
-
Idle
-
Offline
Originally, each refresh recalculated this from raw GPS data.
That meant:
-
Repeating expensive queries
-
CPU-heavy aggregations
-
Slower response times during peak load
We needed a smarter approach.
🔥 Materialized Views: The Game Changer
Instead of calculating vehicle states repeatedly, we pre-computed them.
We introduced a materialized view that:
-
Stores the latest GPS point per vehicle
-
Derives vehicle status
-
Refreshes periodically
Now dashboard queries became trivial:
⚡ Instant results. Minimal load.
☁️ AWS EC2: Scaling Without Overengineering
We ran PostgreSQL on dedicated EC2 instances, tuned for database workloads.
Key decisions:
-
High-RAM EC2 instance
-
SSD-backed storage
-
Proper PostgreSQL memory tuning
-
Connection pooling (PgBouncer)
Instead of blindly scaling horizontally, we:
-
Optimized queries first
-
Reduced unnecessary load
-
Scaled only when metrics justified it
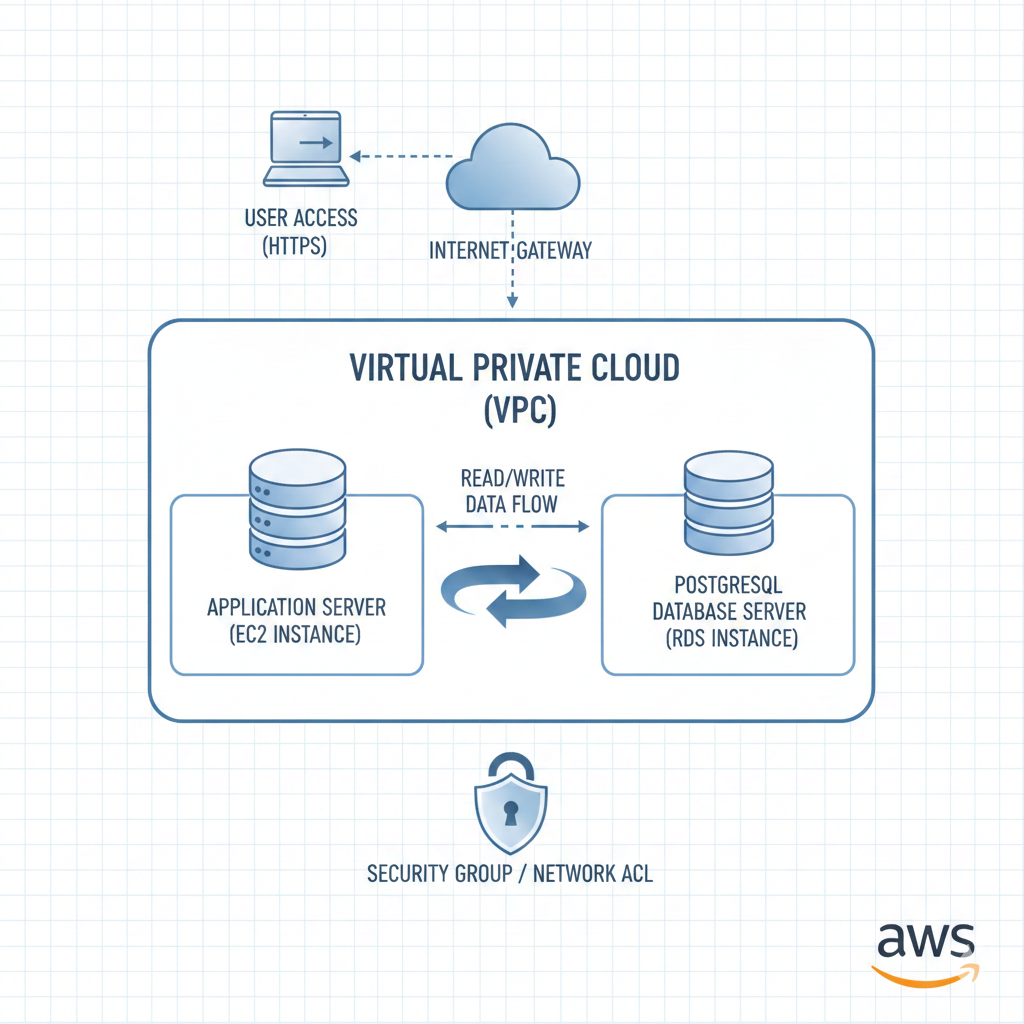
📦 Handling GBs of GPS Data Efficiently
Why this architecture works:
-
Append-only writes keep inserts fast
-
Indexes optimize the most common access patterns
-
Partitioning keeps queries scoped
-
Materialized views eliminate runtime computation
PostgreSQL proved it can comfortably handle:
-
Hundreds of millions of rows
-
Continuous writes
-
Real-time dashboards
🧠 Key Takeaways
If you’re building a GPS or telemetry system:
-
Model data for access patterns, not just schema
-
Index for “latest record” queries
-
Use materialized views for dashboards
-
Partition early — not after performance breaks
-
PostgreSQL is far more powerful than people assume
With the right design, you don’t need exotic databases — just well-used fundamentals.